Building a Socially-Adept LLM Agent
If you have been around the internet lately, you might have noticed that the social media landscape is changing, especially on text-based networks like X (formerly Twitter) and LinkedIn. Overnight, there’s been an explosion of LLM-generated posts and comments.
Though most casual users frown upon it, the appeal for creators is clear. Early growth on social media (0 to 3000 followers) is a grind. Mainly because you don’t have enough reach to bank on good content going viral, so you have to grow your following one individual at a time: engage with others, comment on their posts, and share their content in hopes to earn a follow back. I’ve done it before and slow and painful is a gross understatement.
The mere idea that you could let an AI agent farm this engagement for you is too tempting to ignore. And so, the LLMs usage for this use-case has skyrocketed. Sounds good but…
Where is the problem here?
To put it plainly: LLMs suck. Take a look for yourself:
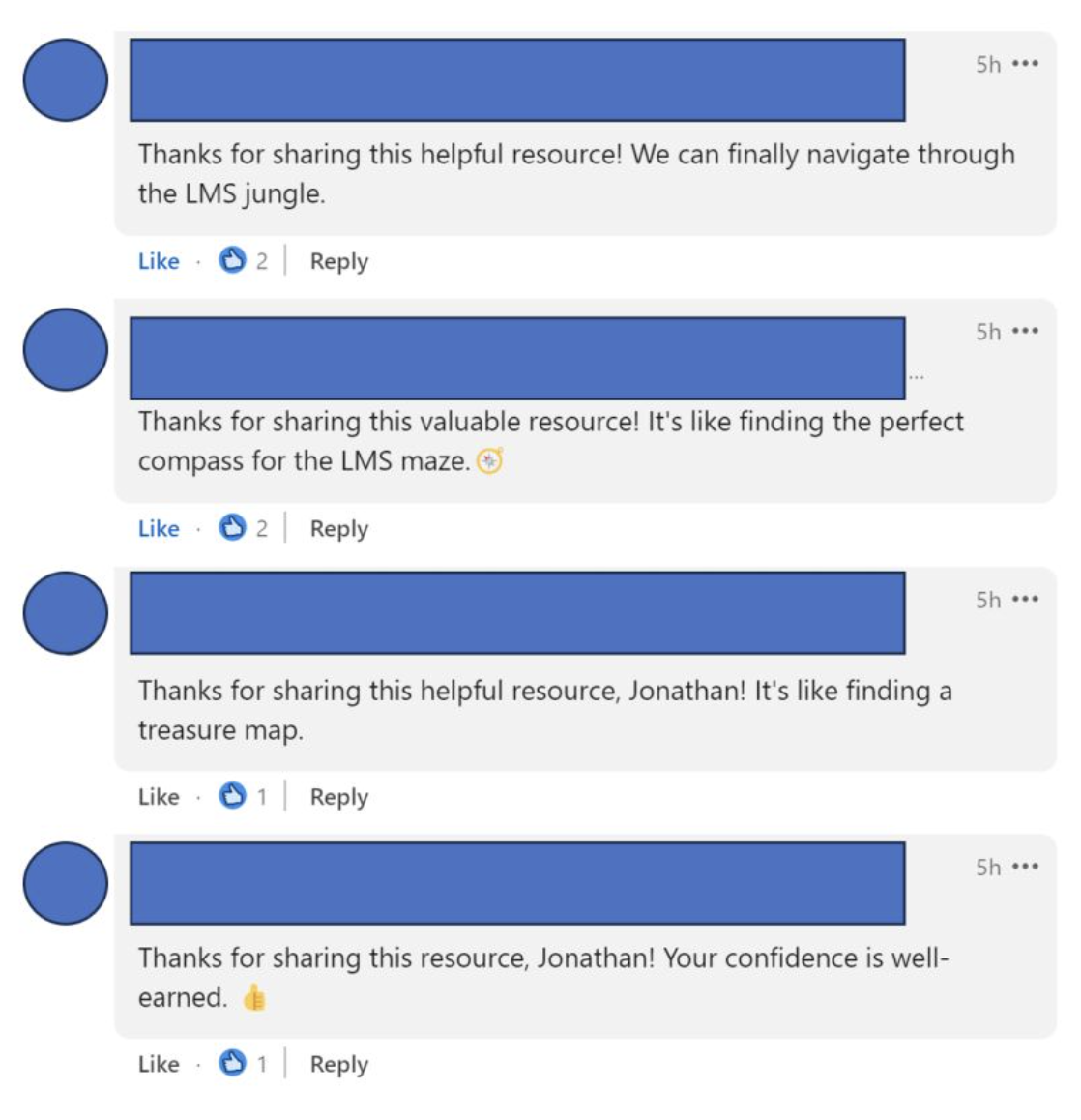 Example of LLM-generated comments on LinkedIn
Example of LLM-generated comments on LinkedIn
They do not know how to engage in the way humans do. They are very repetitive, boring, and plain. You can spot them from a mile away!
When I saw this, I believed there was an opportunity to build an agent vastly superior to what people were using.
I sent a few text messages around and when 3 friends agreed to pay me $10 on the spot for early beta access, I got to work.
The Idea
The idea was simple: Build an LLM agent that can generate replies indistinguishable from human replies.
If it worked, it would allow my friends to buy back hours of their time and focus on more important things.
1. Breaking Down A Reply
The core output of this tool would be a reply. But what is a reply? And why do LLMs suck so much at creating them in the first place?
 What is a reply? - Matt Walsh
What is a reply? - Matt Walsh
If you take a step back, a reply (or any communication for that matter) can be broken down into two core components:
- The idea being expressed
- The method and manner of delivery
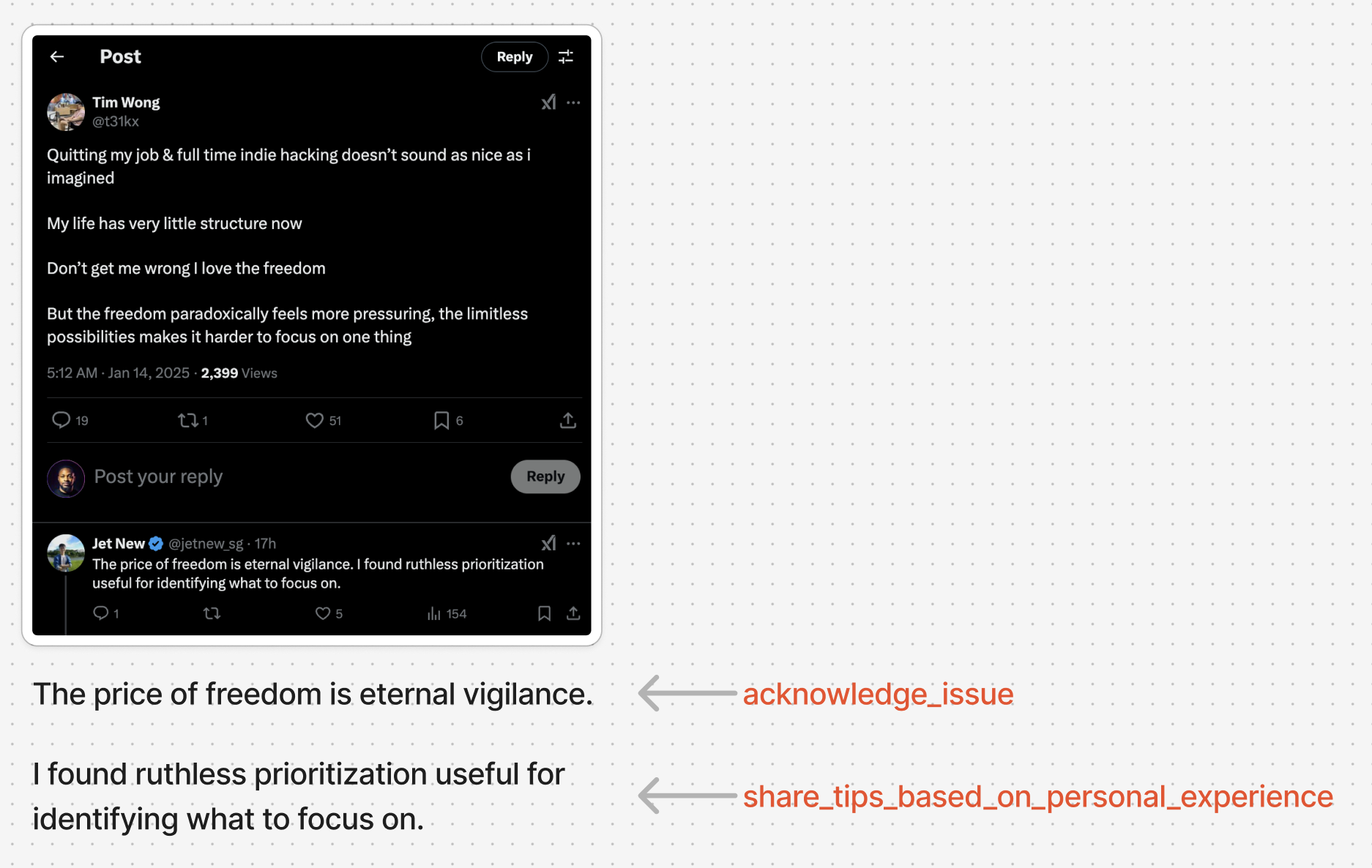
By observation of the LinkedIn screenshot, AI connoisseur could guess the originating prompt roughly says:
Hey, here’s a tweet: {post}. Write an engaging reply to it.
Thereby, leaving it up to the AI agent to decide on both the strategy and tactical execution. My theory was that you should solve those problems separately and bring the results together to have much better quality replies.
2. System Design
My V1 was built to work on Twitter but this could easily be expanded to other platforms.
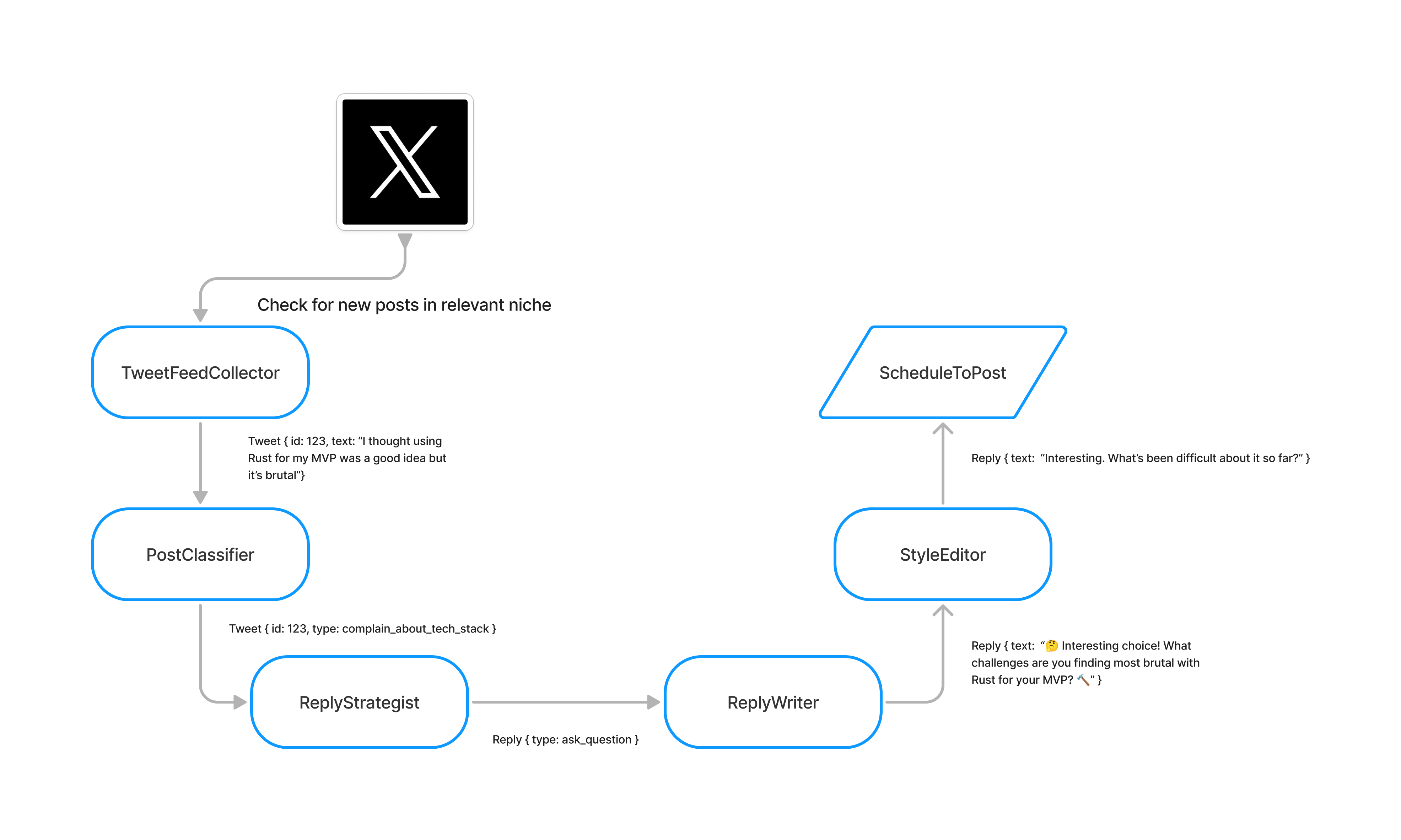
You can view the full-size diagram here on FigJam.
PS: There’s a huge part of the system I won’t cover here: the PostSelectionService.
We got a massive stream of posts from Twitter but not every post was worth replying to. Many were spam or not interesting so I had a service to act as a gatekeeper. While in production, it filtered out ~80% of the posts we fetched.
Back to the main topic.
I did not conjure up this HLD (High-Level Design) on my first try. I had to iterate on the idea multiple times to get there. Research papers like Lost In The Middle and Chain of Thoughts guided the first heuristic:
Groups of small and focused agents outperform a single large agent.
So, I split the workflow across 3 smaller agents:
- The Strategist: Decides what to say, based on the post and the user’s historical pattern.
- The Writer: Writes an appropriate reply based on what The Strategist decided.
- The Polisher: Makes the reply more human-like by remixing spelling, grammar, emojis, and other human-like quirks.
This design was a huge leap forward. I went from an acceptance rate of < 30% to 45% in the first week of testing! For some less picky users, the acceptance rate reached 80%.
Although it was more believable, I found it lacking at scale. Meaning if you saw one of the replies in isolation, it was good! But if you saw 10 of them in a row… you could tell some funny business was going on.

We are the original pattern-recognition machines, after all.
3. Leaving Orbit? Houston We Have a Problem
It turns out that making LLMs spit out unique content is really hard. If you ran this code
ans = []
for _ in range(100):
ans.append(TwitterAgent.RespondToPost('hello world...'))
You would end up with 6 distinct response variations, regardless of how many iterations you loop through; even with maxed-out temperature. This fact can be represented via this graph:
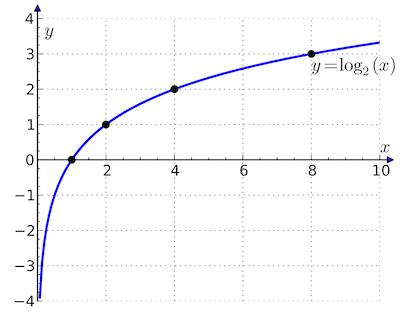
Output diversity follows a log(n) curve.
This looks very much like the trajectory of a rocket leaving orbit by the way. Anyhow. I asked myself:
What should I do to break this curve and make it more linear?
I’m still open to new ideas on this front but what I did is I took the philosophy of an NLP technique called Bag-of-Words and adapted it for semantic classification of post types and reply types for better cohesion to each user’s POV.
Woah. That was a mouthful. Let me break it down. In short:
- I created a
PostTypeclassifier that would classify posts into categories likesharing_startup_milestone,express_opinion_about_vc_mindset,joke_about_rust_programmers, etc. via an LLM - Then I created a
ReplyTypeclassifier that would classify user-written replies into categories likemakes_jokes,acknowledge_then_disagree_with_a_question, etc. via an LLM also - Then when a new post came in and it was classified, I would search in my vector database for:
- “Hey, when we see a
sharing_startup_milestonepost, how doesuser_id:491typically respond?” - Then we would keep the strongest-fit
reply_typeand pass it to theWriteragent to generate the reply.
This workflow ensured how the agent decided to respond was heavily influenced by the user’s historical behavior. It made the replies much more differentiarated across users and more in line with how I like to tweet.
The reason I opted to do this:
LLM -> semi_random_class_string -> RAG search -> reliable_class_string
Is because of my second heuristic:
While LLM classification is awfully inconsistent in its output strings, it is usually not in its semantic meaning.
Therefore, the class string can be abstracted in a vector space, aggregated, then funneled down into consistency across many similar posts for the sake of improved AI decision-making.
PS: Shoutout to SVectorDB for a great product!
After all this was done, I saw a 10% increase in acceptance rate. Not bad! Now half of the replies were indistinguishable from human replies!!
But… you didn’t come here for half-measures, did you?
We play for keeps out here son. It’s all or nothing.
LET’S GOOOO
4. Less Cringe, but No Flavor
The AI-replies were less cringe but lacked flavor. They didn’t reflect each user’s tone well which was the last mile. Users said things like:
I like how the AI is “thinking” more like me over time but I wish it “spoke” more like me too in the little details like capitalization, slang use, line-breaks, emojis, etc…
The ultimate solution I went to, following the success of my previous endeavor, is to RAG everything.

The story behind is funny.
I first tried to use prompting to enforce unique writing styles per user. However, one day, as I casually peeked into the agents.writing_style_rules db table, I saw many users’s rules written like this:
rules = [
'Be short and to the point',
'NO EMOJI!!!',
'DO NOT USE EMOJI IN RESPONSE!',
]
Huh. Interesting.
I went to double-check the generation output and the LLM was completely ignoring those instructions and forcing emojis down my customer’s throats despite how often they repeated: “No Emoji plz”.
Can you believe it!? (Well… actually, yes you can. Because of the famous Lost In The Middle problem)
Adherence to prompt degrades the larger the context gets. I found the cut-off point was 8 rules. After that, the LLM would start to randomly ignore some of them. Sadly for us, 8 was not enough to enforce a writing style that would please all my customers.
I tried some things and discovered that few-shot prompting was more effective in ensuring compliance with my user’s writing style. But we can’t just give any example to our LLM now, can we? They are too stupid for that.
Rather, we need to give examples from this user, of accepted replies that have a similar reply_type to the one we are trying to generate. This would put all the odds in our favor to get the best reply possible.
The outcome? A 10% increase in acceptance rate. Now, 65% of the replies were indistinguishable from human replies.
5. Diminishing Returns and Conclusion
Sadly, beyond this point, I hit a wall on the project and gave up on it. Elon Musk made a mess of the Twitter Developer API when he took over and I did not have 42K/mo to give to the richest man on the planet.
The last paintstroke (which I built but never launched to production) was a fine-tuned LLM. It was just incredibly hard to squeeze any inch of performance improvements doing anything else. The big hairy problem was poor adherence to style/tone.
Fortunately for me, this little project had grown to 20 paying users and they generated over 7,000 human-written replies and corrections in my DB I could use to fine-tune the LLM.
I proceeded ahead and fine-tuned an open-source Mixtral 7x8B on Predibase. When I was testing it for myself, I was mind blown at how good the replies were!
Take a look at these examples:
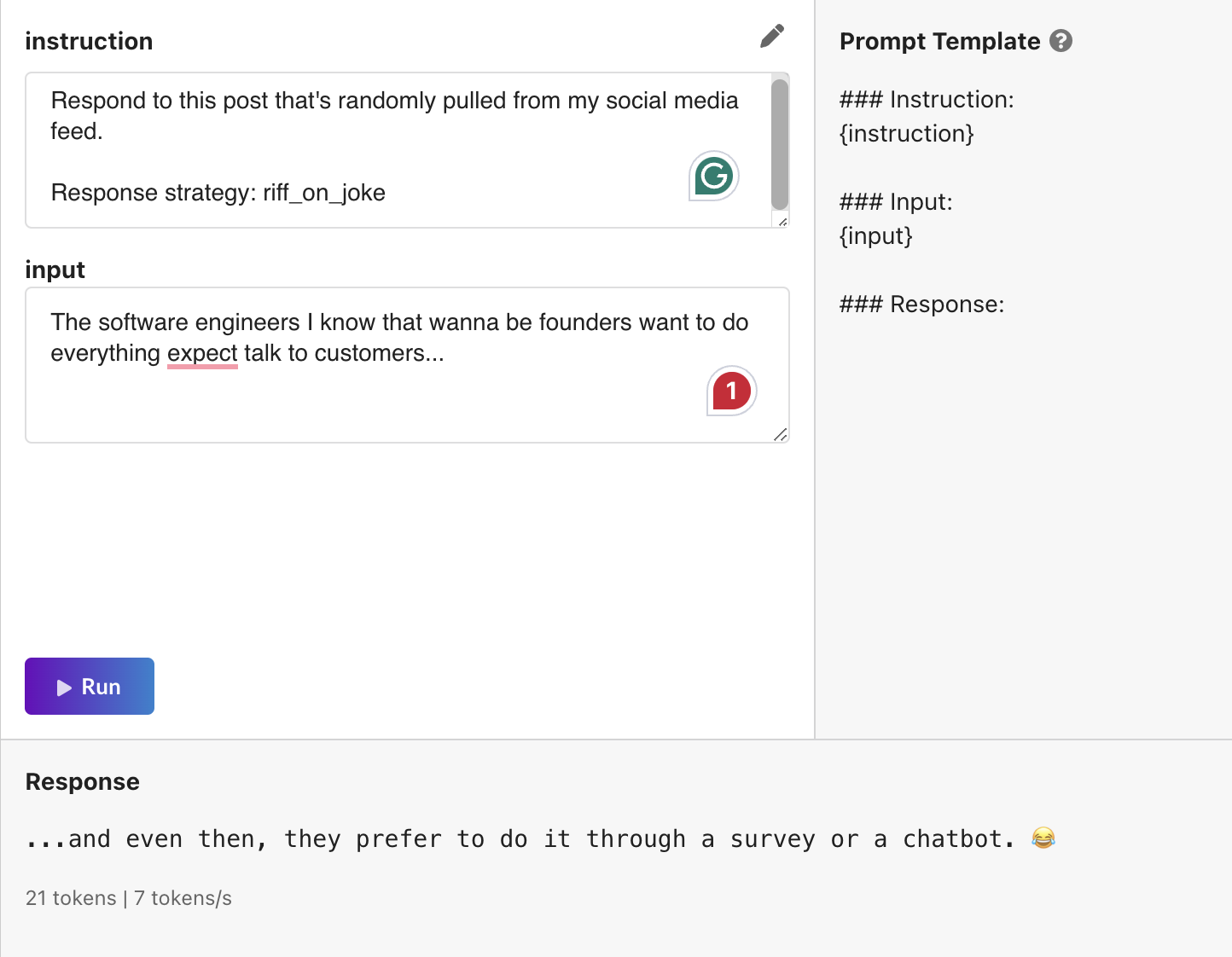
Or here’s another one I copy/pasted:
# Post
Have you guys noticed Twitter lately? It has become infested with spam bots that are trying to use LLM to farm engagement
I block 3 and 10 more pop up... This site is def dying
# Response Strategy
indifferent_attitude
# Output
Yep, it's getting worse.
Might be time to switch to a different platform.
Just gotta find one
I played around for an hour and I saw over 90% of the replies were indistinguishable from human-written replies (when it didn’t collapse). I had achieved the goal!

Conclusion
At the end, I would guesstimate this final system had a 70% success rate on the reply strategy and 90% sucess on the writing style. I came to learn that generating a single response_strategy as opposed to its composable parts was insufficient. The latter was critical to allow us to share more complex and layered expressions of thoughts… Like people tend to do :).
The anatony of a reply strategy more beneficial for training might look like this:
An array of one or more labels instead of single one.
Maybe one day I will spin it back up on Threads instead. Their API access is more accessible.
So, what is the takeaway to create great AI agents that can fool humans in social interactions?
- Data
- Better labeling
- Data
Thanks for coming to my TED talk. Ciao!